


DALL-E 2 üzerinden Diffusion tekniğini açıklıyoruz!
Diffusion mimarisi ile inşa edilen yapay zeka modelleri son zamanlarda genel kitleye oldukça hitap eden uygulamalarıyla tanıtıldı.


Örnek vermek gerekirse OpenAI tarafından geliştirilen “DALL-E 2” ilk diffusion modelini kullanan model olarak biliniyor. Bunun yanında OpenAI’nin veri setine benzer bir veri setiyle eğitilen “Stable Diffusion” ise diffusion mimari kullanan devasa bir boyuttaki ilk açık kaynak projedir.
Önceki Modeller
Tabii ki DALL-E 2 öncesinde de üretken modellerin popülerliği yadsınamaz fakat aşırı absürt ve gerçeklikten uzak sonuçlarıyla tam “performanslı” gibi durmuyorlardı. Bunlardan birine örnek vermek gerekirse GAN modelleri, App Store ve Play Store’de bulunan çoğu uygulamada görebileceğiniz modellerdir.

Yine OpenAI tarafından yayınlanan CLIP, bir üretken olmasa da üretkenlerle harika iş çıkartan ve birden çok amaca hitap eden ilk model olmasıyla bilinir. Hem yazı, hem de görsel için bir çözücü bir de üretici işlevi vardır. Yani hem görselleri detaylı bir şekilde açıklayabilir, hem de açıklamalardan görseller üretilmesi için açıklamaları uygun veriye dönüştürebilir. Yukarıda gördüğünüz görsel ise bir GAN mimarisi olan VQGAN ve CLIP modellerinin bir arada kullanımından ortaya çıkan oldukça sürrealist ve bir o kadar da gerçek dışı sonuçlar veren sonuçlarıdır. CLIP’in işlevinin burada çözücü ve açıklayıcı olduğunun altını çizmek faydalı olacaktır.

Görselde ise hem veri setinin büyüklüğü hem de arkaplandaki modelin değişkenliğiyle artan kalite farkını gözlemliyorsunuz.
CLIP mimarisini elbette ki bu kadar kısa anlatmakla yetinmemiz mümkün değil ancak bu yazımızın konusu Diffusion mimarisi olduğundan onları DALL-E 2 örneği üzerinden açıklamamız daha mantıklı olacaktır.
DALL-E 2
Diffusion mimarisi DALL-E 2 mimarisi içerisinde CLIP modelinin herhangi bir açıklamayı uygun hale getirmek için kullanımı sonrasında, bu biçimlendirilmiş açıklama “Prior” bölümü için kullanılır. Diffusion burada CLIP kısmından gelen biçimlendirilmiş açıklamayı olabildiğince anlamına uygun bir görsele dönüştürür.
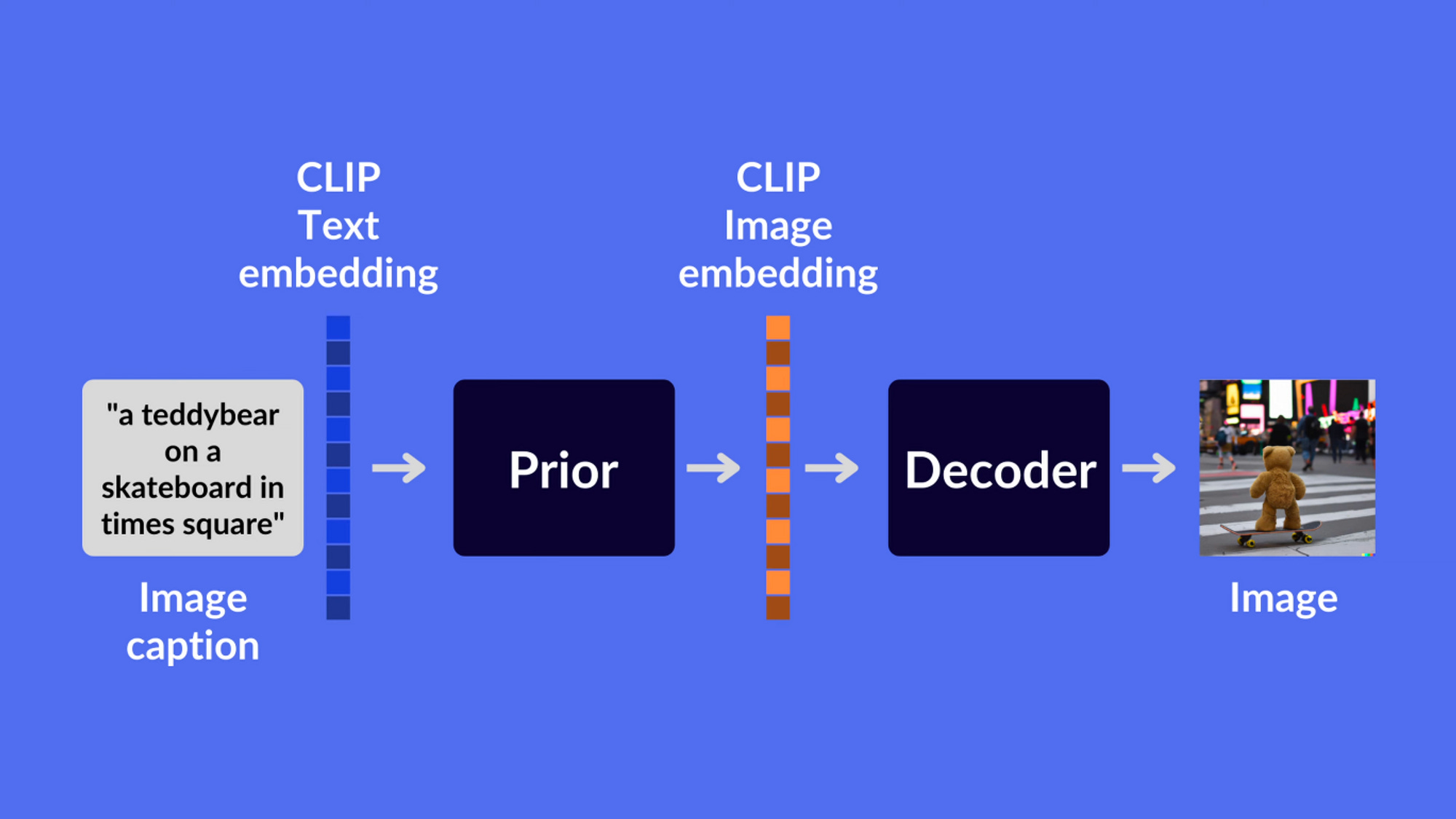
Peki bu dönüştürme işlemi nasıl gerçekleşiyor?
Diffusion tekniği, bir görsele Markov Zinciri kullanarak yani zincirdeki her bir nesneyi ancak kendisinden önceki nesnenin etkileyebileceği şeklinde kurulan zincirlemede sürekli bir şekilde adım adım ‘noise’ eklenerek iyice gürültülü bir hale gelene kadar tamamlanması sürecini kullanarak uygulanır. Bu adımlardan sonra teknik kendini geriye sarıp bir görselin saf gürültüden nasıl oluşabileceğini kavramaya çalışır.

Bu adımlardan sonra bir görsel ortaya çıkar ve bu görsel kendisini betimleyecek olan CLIP betimleyicisine aktarılır. CLIP betimleyicisi burada verilen görseli bir metin olarak betimleyip uygun hale getirir ve bu metin tekrardan “Decoder” adı verilen diffusion tekniğine sahip başka bir alana aktarılır.
Yine aynı şekilde “Prior” kısmında olduğu gibi diffusion tekniği ile bir betimleme metninden görsel oluşturulur ve bu görsel size çıktı olarak verilen görseldir.
Gördüğümüz gibi diffusion tekniğinin burada CLIP ile bütünleşik bir şekilde veri setinden uygun görselin aktarılarak betimlenmesi sonucu bambaşka bir görsel daha üretiliyor ve bu üretilen görsele verdiğimiz özellikler de etki ediyor. Aynı zamanda upscaling yöntemleriyle de çıkan sonuç daha yüksek kaliteye sahip oluyor.
Eğer ki diffusion kullanarak geliştirilmiş modelleri projenizde kullanmak isterseniz HuggingFace bunu sağlıyor. Kesinlikle kullanmanızı öneriyoruz.
Uğur Akdoğan
Bu yazımızda da size Diffusion algoritmasının üretken yapay zeka modellerinde (GAN) nasıl efektif bir biçimde mimariye dahil edildiğini anlattık. Sonraki yazılarımız için bizi takip etmeyi unutmayın.
Geri bildirimleriniz bizim için son derece önemli, yorumlarınızla daha iyi bültenler hazırlamamıza ve büyümemize destek olun.
 | A guest post by
|